怎么理解存储的可用性?什么是5个9,6个9,7个9?
引言
最近在接触潜在客户的过程中,经常会被问到类似的问题,比如:“我们的主存储是三副本的,为什么还需要备份?”,或者说:“我们用的云存储的SLA已经满足了我们的要求,数据的备份好像不是很必要”。这篇文章主要想从数据风险的角度,谈一谈关于存储的可用性的看法。
数据风险
数据风险来源于何处?下面这张图对所有的可能做了一个简单的总结:

通常来说,我们可以把风险分为软硬件系统本身的失效或者错误,或者其它因素,这里列出的是自然灾害和人为因素。对于后者,大多数读者多少应该都会有一些听闻。所谓“好事不出门,坏事传千里”,一旦遇到火灾、删库跑路、病毒勒索等导致的数据丢失等重大事件,各大媒体公众号一定会争相报道。而对于前者,例如某个客户用了某家厂商的存储系统因为系统本身的软硬件故障造成了哪些重大的影响,却很少有人知道。除非是某个公有云厂商系统故障造成了大规模的影响,由于影响面比较大,才会被报道。这是由于,如果某个客户花重金购买了某个厂商号称可用性有5个9、6个9甚至7个9的存储系统,如果遇到了系统宕机、应用中断甚至数据丢失这样的黑天鹅事件,虽然影响甚大,但这属于“家丑不可外扬”,厂商也会尽力安抚客户,自然不会往外宣传。
本文主要针对第一个因素对数据的风险进行一些探讨,让读者对存储系统的黑天鹅事件有一个更加直观的理解。
主存储的可用性和持久性
首先我们来看一看主存储的衡量指标。当衡量系统的可靠性时,一般会涉及到两个概念,可用性(availability)和持久性(durability)。
可用性一般是指系统不中断服务的时间占实际运行时间的比例。IBM Z,IBM DS8900F的白皮书宣称可用性是7个9。Wikipedia对High avaliability有一个表,列出了每一个百分比对应的宕机时间参考:
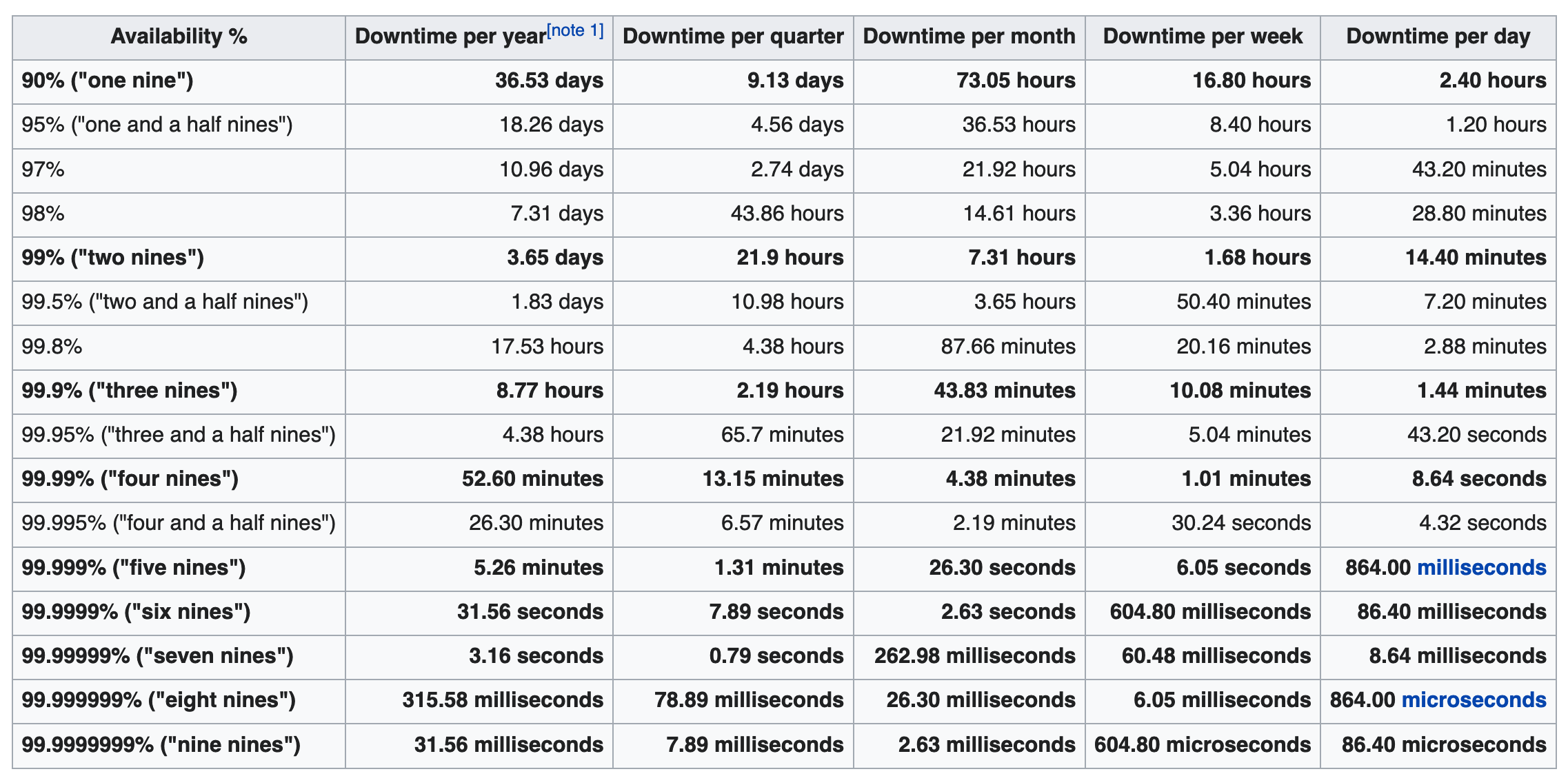
可以看到,当系统的可用性到5个9及以上时,系统平均每年的宕机时间在6分钟以内,基本可以满足大部分公司的需要了。
持久性跟可靠性经常会相互混用,持久性是更加精确的说法,是指系统维持数据一致性的能力。持久性比可用性的9的数量更多,因为系统遇到软硬件错误时,大部分情况首先会造成系统不可用,其中又有少数情况会造成数据丢失。当然,也有系统一直可用,但数据丢失的情况,在业界称为Silent data corruption,这种情况更为罕见。
对于持久性的计算,业界并没有统一的计算公式,参考5知乎的一篇文章给出了一个计算方法,参考9中synology给出了一个更简单的公式。对于实际的产品,AWS的S3对象存储给出的是11个9,阿里云OSS给出的是12个9。那11个9的持久性意味着什么呢?synology的文章给出的一个解释:相当于如果你存了1千万个对象,那平均期望每10000年丢失一个对象。然而,对于传统的存储厂商的存储产品,网上只能找到可用性的数值,找不到持久性的具体数值。参考8中wasabi的文章说,云存储的持久性比私有部署的磁盘阵列形式的存储更可靠。从技术上来说,其实非常可能。因为云存储的在规模方面有很大的优势,可以以较低的成本实现多副本或纠删码,区域隔离等技术手段,让数据的持久性更高。
主存储的黑天鹅事件
上一节简单介绍了主存储的可用性和持久性,并列举了一些主流的厂商的数据。单从数据来看,不论是系统宕机,还是数据丢失,看起来主流厂商提供的可用性和持久性已经非常好了。例如,如果客户购买了一台可用性为7个9的存储系统,那平均一年只有3秒钟的宕机时间。而如果存储系统有11个9的数据持久性,存1千万个对象,每10000年才会丢失一个对象。
那么存储系统的黑天鹅事件是什么呢?首先让先我们来总结一下:
- 系统宕机,数据不可访问
- 系统没有宕机,但是应用的数据无法访问
- 系统宕机恢复之后,或者报故障之后,报告数据丢失
这几种问题可以归结为数据不可用和数据损坏,对没有配置灾备站点、不能及时切换服务的客户来说,基本上每一个问题都是非常严重的,意味着系统在恢复之前,都不能继续服务了。而数据丢失,那就是存储系统最严重的错误,没有之一,客户遇到这个问题,即使有备份,都会非常生气,难以接受。
等等,前面那个可用性的表里,不是说5个9的可用性,每年就几分钟宕机时间嘛,7个9的话,只有3秒钟,即使遇到问题,应该很快就恢复了才对?
就这个问题,以本人在某外企高端存储开发团队工作多年经验来看,当黑天鹅事件发生时,有相当比例的事件,都会造成数小时的宕机。而数据丢失事件也绝不是销售人员口中的“小概率事件”。那么,究竟是哪里不对呢?
这是由于,人们对概率的理解往往存在两大偏差:
- 平均往往隐藏了极端情况
- 集合概率与时间概率
对第一种偏差,这里举一个简单的例子。假如你在野外遇到一条宽10米、平均深1米的河,你到底选择徒步过河还是不过河?只有平均数值的情况下,看起来风险很小,然而,如果不知道最深处有多少米,最好还是别过河。因为野外遇到的平均深1米的河,不太可能想下面A这样平坦;也许会想B这样,大部分不到1米,少部分深2米;甚至像C这样,绝大部分很浅,但有一个很深的坑。

这里我们可以看出,平均数值往往隐藏了很多信息,比如最好与最差。我们在学校学习的统计,往往会把离群值去掉,再计算平均值或者方差。然而现实生活中,往往最好或者最差值对结果有着至关重要的影响。存储厂商往往只披露可用性的平均值,而不会(你很难从网上查到,不过参考6给出了IBM服务器超过4小时宕机的情况)披露最差值。假设全球有10万台可用性是7个9的存储系统在运行,每年出现的问题往往不是每台机器出现几秒钟的短暂故障,也不是20%的机器出现几分钟的宕机,其它机器都没问题,而很可能是其中99950多台机器都没有明显问题,而不到50台机器会出现数小时的黑天鹅事件,平均一下,还是基本符合7个9的可用性。
对第二种偏差,《随机漫步的傻瓜》中提到一个非常有意思的思维游戏:一群人玩俄罗斯轮盘赌一天的平均收益与一个人玩俄罗斯轮盘赌100天的收益是完全不一样的。现在我们来替换几个数字,重新定义一下这个思维游戏。假设用一把装弹量为10万发的手枪玩俄罗斯轮盘赌,有10万个人来玩这个游戏,就玩一天。对局外人来说,只有10万分之一的概率会爆仓出局,参与赌局的收益率是99.99999%。然而,如果我们写一个小程序,让变量X来每秒钟玩一次这个游戏,我们无法知道X什么时候会被一枪毙命,但是我们可以非常肯定的说,X迟早会Game Over。
因此,100个赌徒在1天时间里的成功概率,并不适用于一个人在100天时间里的赌运。即使再小的概率,如果一直不断重复的暴露在风险之中,最终爆仓的概率将会越来越接近100%。1千万个对象10000年看起来很遥远,wasabi的文章给出的是1个PB的数据(12亿个对象)平均8年丢失一个对象,是不是近了很多?
其它风险
看完了系统本身的风险,让我们再来看看其它风险。对于自然灾害,如地震火灾这类风险,比较大的数据中心一般都会考虑到这种风险,在规划设计时会用冗余来保证整体的可靠性。但是对于比较小的数据中心,或者中小客户,可能很难用冗余的方式来抵御这种风险,毕竟容灾系统的成本还是比较高的。再加上对于危急数据中心的自然灾害本身来说,就非常难得一见。笔者也没有找到有哪篇文章阐述了自然灾害对存储系统或者数据中心的风险排行。
对于人为因素,各个参考都给出了较高的排名。wasabi给出的前5个数据风险的饼图中,硬件故障+软件故障占49%,其余3种都是人为因素,占51%。参考6中ITIC对人为失误给出了更广泛的定义,并且问卷调查显示超过50%的调查对象认为人为失误占系统可靠性问题的第一位。对数据安全类问题,例如数据泄露等,82%的调查对象都认为是头号问题。
对于人为因素导致的数据风险,不像软硬件系统本身,可以有量化的公式来计算一个具体的数值,相反,人为因素是非常不确定的。通过前一节的分析,我们可以看到即使对于软硬件系统非常精确的一个数值,理论的数值与在现实中的表现也会有很大的偏差。那么对于本身就非常不确定的因素,在现实中会更难把握这些因素导致的风险。
如何应对
看到这里,相信读者存储系统的风险有了更深的认识,不论现在用的系统有多可靠,总会有已知(软硬件系统本身)或者未知(自然、人为因素)的风险。不管是已知因素,还是未知因素,对系统的风险都不是0。只要风险不是0,那么首要考虑的问题就是,当黑天鹅来临之时,对系统的影响是否可以接受。如果答案是否定的,那么要做的事情就很简单,为可能到来的黑天鹅准备好应对措施。
参考
1. High Availablility
2. IBM DS8900F Data Sheet
3. IBM Z
4. 云存储中那么多“9”的来历(一)—— 持久性与可用性
5. 云存储中那么多“9”的来历(二)—— 持久性的数学计算过程
6. ITIC 2017–2018Global Server Hardware, Server OS Reliability Report
7. IBM Mainframes and Power Systems continue to deliver unsurpassed reliability
8. wasabi - What Does 11 Nines of Durability Really Mean?
9. synology - data durability